

Spark追妻系列(Pair类型算子)
感觉今天元气慢慢,又是更文的一天
小谈
最近感觉更文的劲头不大,打游戏的尽头也不大,八成是在摆烂了
现在开始更新的是key -value类型的算子了,也就是键值对操作,所谓的键值对类型也就是Pair。
创建PairRDD
很多存储键值对的数据格式会在读取时直接返回由其键值对数据组成的Pair RDD。当需要把一个普通的RDD,也就是Value 类型的RDD转换为pair RDD时,可以调用map()函数来实现,传递的函数需要返回键值对,。
下面举个例子,
val pairs = lines.map(x => (x.split(" ")(0), x))返回的就是键值对类型
PartitionBy
将RDD[K,V]的k按照指定的Partitioner重新进行分区,如果原有的partitionRDD和现有的分区规则一样,就不会分区,如果不一样会产生shuffle操作。
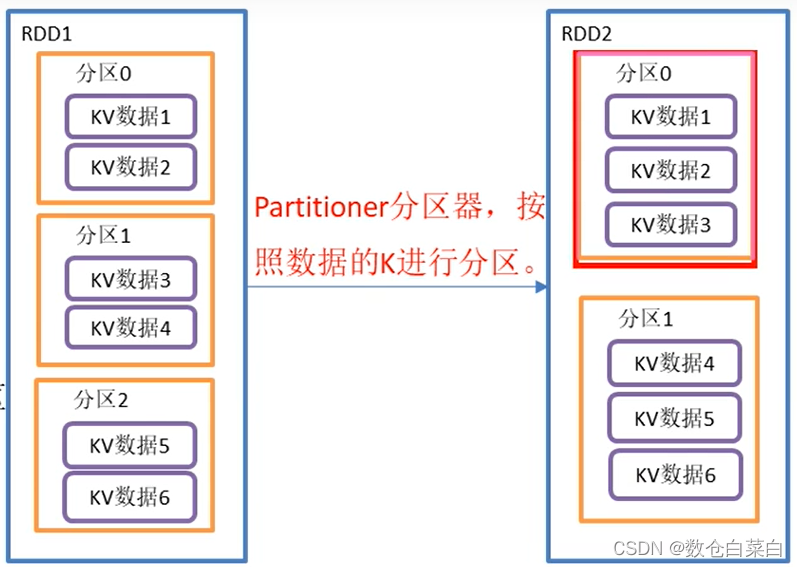

现在看一下下面的代码
val wordCount = new SparkConf().setMaster("local").setAppName("WordCount")
val sparkContext = new SparkContext(wordCount)
val value = sparkContext.makeRDD(List(4, 3, 1, 2))
value.partitionBy()系统会爆错,为什么呢?
因为partitionBy是Pair RDD,但是上面的makeRDD返回的只是Value类型的。并不是key value类型的
下面通过一个代码来看一下partitionBy的操作
val wordCount = new SparkConf().setMaster("local").setAppName("WordCount")
val sparkContext = new SparkContext(wordCount)
val value1 = sparkContext.makeRDD(List((1, "aaa"), (2, "bbb"), (3, "ccc")), 3)
//来看一下每个分区里面的数据
value1.mapPartitionsWithIndex( (index, iter) => {
println(index + "没有partitionby" + iter.mkString(","))
iter } ).collect()
//将3个分区 转变成 2个分区
val value = value1.partitionBy(new HashPartitioner((2)))
val value2 = value.mapPartitionsWithIndex(
(index, iter) => {
println(index + "partitionby之后" + iter.mkString(",")) iter } ).collect()
看一下输出的结果
0 没有partitionby (1,aaa)
1 没有partitionby (2,bbb)
2 没有partitionby (3,ccc)
0 partitionby之后 (2,bbb)
1 partitionby之后 (1,aaa),(3,ccc)
上面就是最后输出的结果
在刚开始创建rdd的时候,分区情况是这样的
分区0 (1,aaa)
分区1 (2,bbb)
分区2 (3,ccc)
partitionBY中使用了哈希分区器,分了两个区
分区0 (2,bbb)
分区1 (1,aaa),(3,ccc)
可能不懂为什么是这样分区的,来看一下HashPartitioner的源码
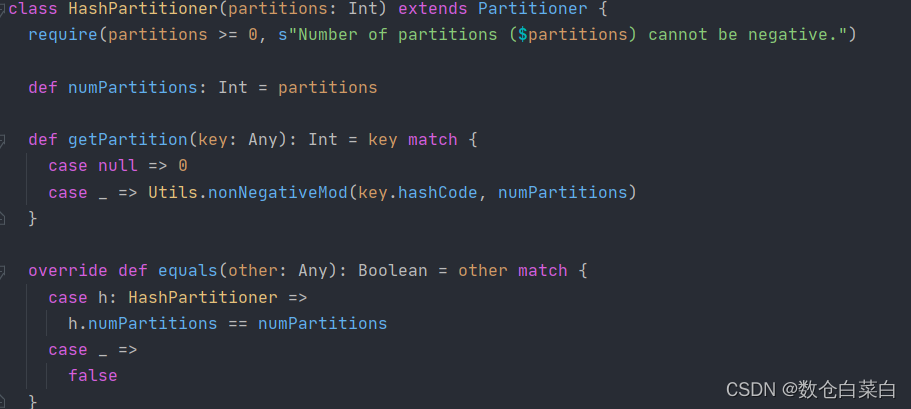
来看看getPartition方法,k的哈希值 % 分区的数量 当作分区的凭证
当然了,分了两个分区,最后的模不过就是 0 或者 1
分区数量减少了,发生了shuffle
在本地的执行计划当中也可以看到是否有shuffle
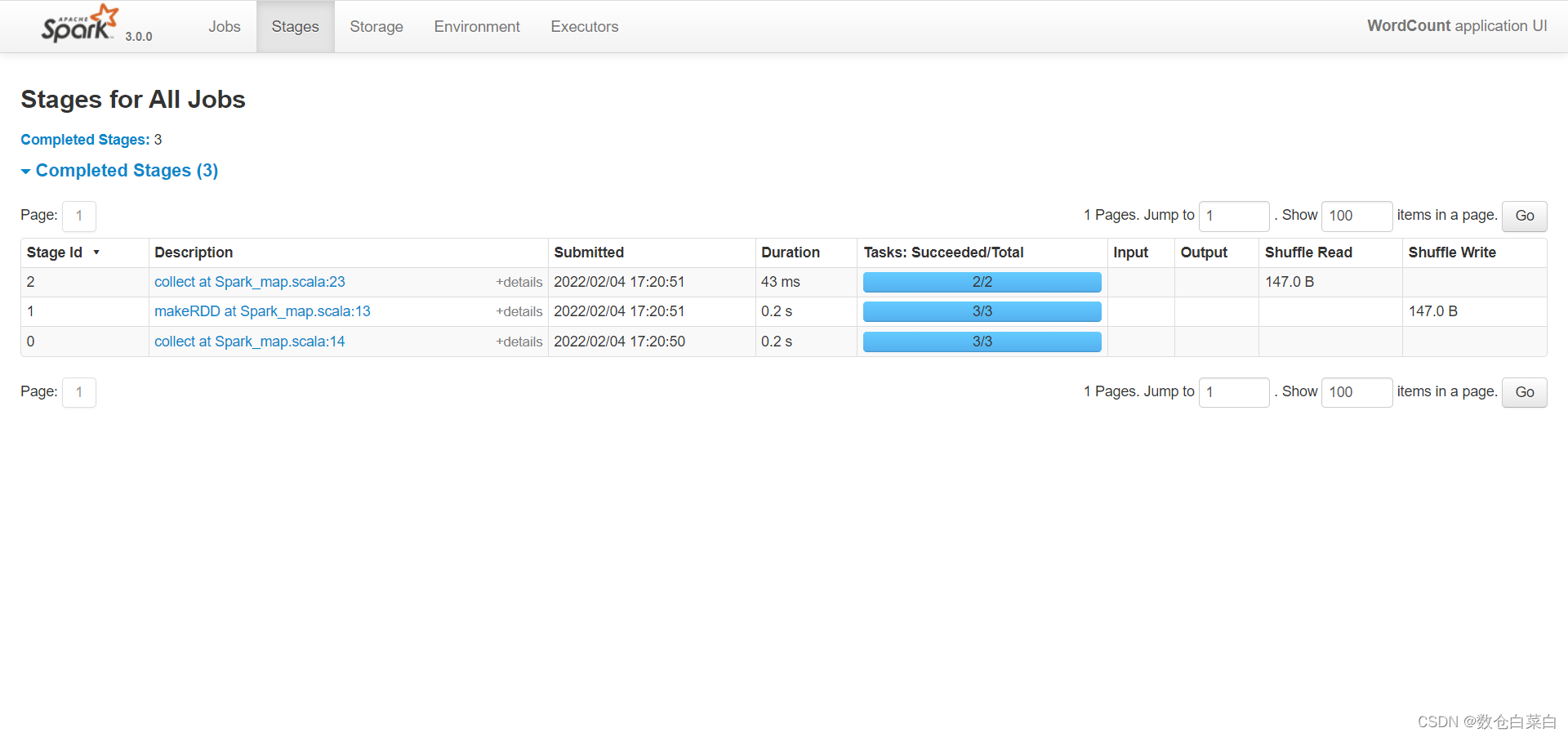
可以看到,发生了shuffle,数据被打乱了。这时候有疑问了,如果刚开始创建的时候是一个分区,分区之后也设置一个分区,都是一个分区,那数据还会shuffle吗
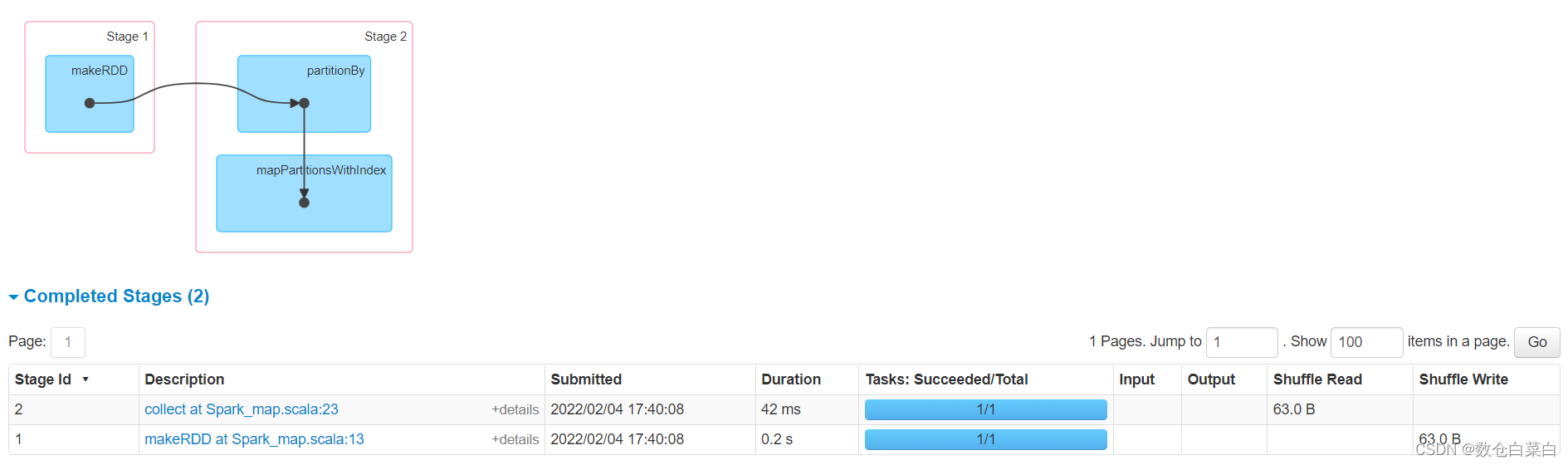
结果很明显,依旧会有shuffle阶段,为什么分区数都设置成一个了还是会有shuffle呢
因为在使用分区器的时候,底层会new shufflerRDD
自定义分区器
上面演示的时候,用的分区器是默认的hashPartitioner分区器,就像mr程序一样,也可以自定义分区器,根据自己的设定来进行分区。
要实现分区的功能,需要继承Partitioner
下面来实现自定义分区器
List(("135", "aaa"), (1, "bbb"), ("ll", "ccc")
如果是字符串类型 以135开头 放到分区0里面
不是135开头 放到分区1
如果不是字符串类型 放到分区2里面 总共三个分区
val wordCount = new SparkConf().setMaster("local").setAppName("WordCount")
val sparkContext = new SparkContext(wordCount)
val value1 = sparkContext.makeRDD(List(("135", "aaa"), (1, "bbb"), ("ll", "ccc")), 1)
//通过实现自定义分区器
val value = value1.partitionBy(new MyPartitioner(3))
//打印每个数据及其所在的分区 value.mapPartitionsWithIndex(
(index,iter) => { println(index +" " + iter.mkString(","))
iter } ).collect()
Thread.sleep(1000000) }
//定义分区器
class MyPartitioner(partitions: Int) extends Partitioner{
//实现自定义分区器的时候指定的分区个数
override def numPartitions: Int = partitions
//重写分区规则
override def getPartition(key: Any): Int = {
if(key.isInstanceOf[String]){
val str = key.asInstanceOf[String]
if(str.startsWith("135")){
return 0 }else{
return 1 } }
else{ 2 } } }按照上面所说的规则,最后的结果就是
0 (135,aaa)
1 (ll,ccc)
2 (1,bbb)
如果以135开头,就放到分区0 不是135开头就放到分区1里面,不是字符串类型放到分区2里面。完美的通过自定义分区器实现要求的分区规则。
关于分区器这一片,之后也会将那些分区器都按照源码解析一遍,到时候会给大家写上一篇文章来介绍一下这些分区器
reduceBykey
这个算子可以根据相同的key,对value进行聚合
先看一下图解
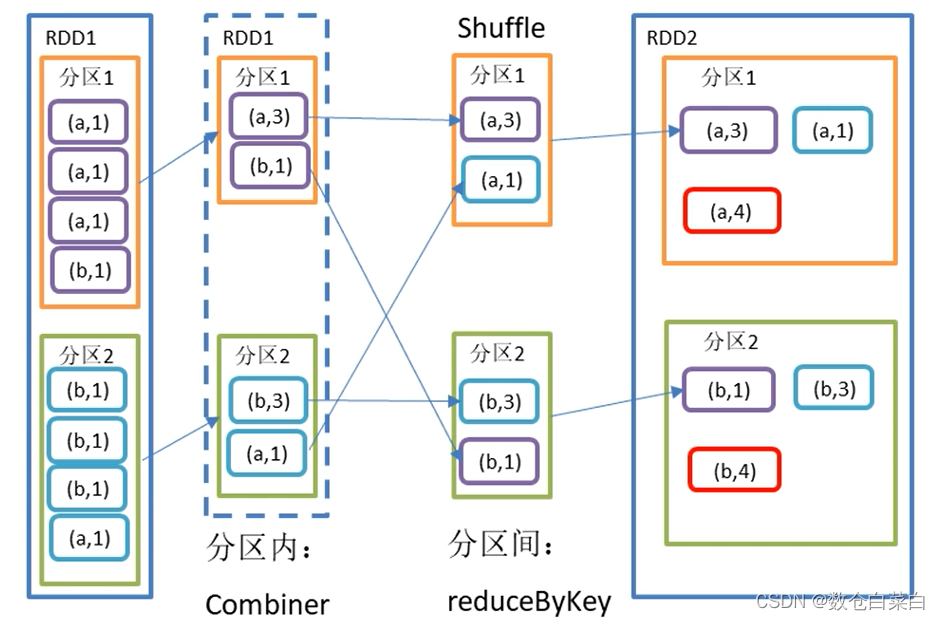
首先看分区1里面的数据
(a,1) (a,1) (a,1) (b,1)
现在分区1里面举行预聚合 (a,3) (b,1)
之后就会shuffle,在不同分区里面进行聚合。
(a,3) (a,1)
然后进行最终的聚合 (a,4)
下面看一段代码
val wordCount = new SparkConf().setMaster("local").setAppName("WordCount")
val sparkContext = new SparkContext(wordCount)
val value1 = sparkContext.makeRDD(List(("a", 1), ("b", 12), ("a", 12)),2)
//对相同的key进行相加
val value = value1.reduceByKey(_ + _)
//看每个分区的数据
value.mapPartitionsWithIndex( (index,iter) => {
println(index+" " + iter.mkString(",")) iter } ).collect()先看结果
0 (b,12) 1 (a,13)
分区0 里面的key是b 分区1类里面的key是a
这个算子里面会发生shuffle,不相信的话来看一下本地任务把
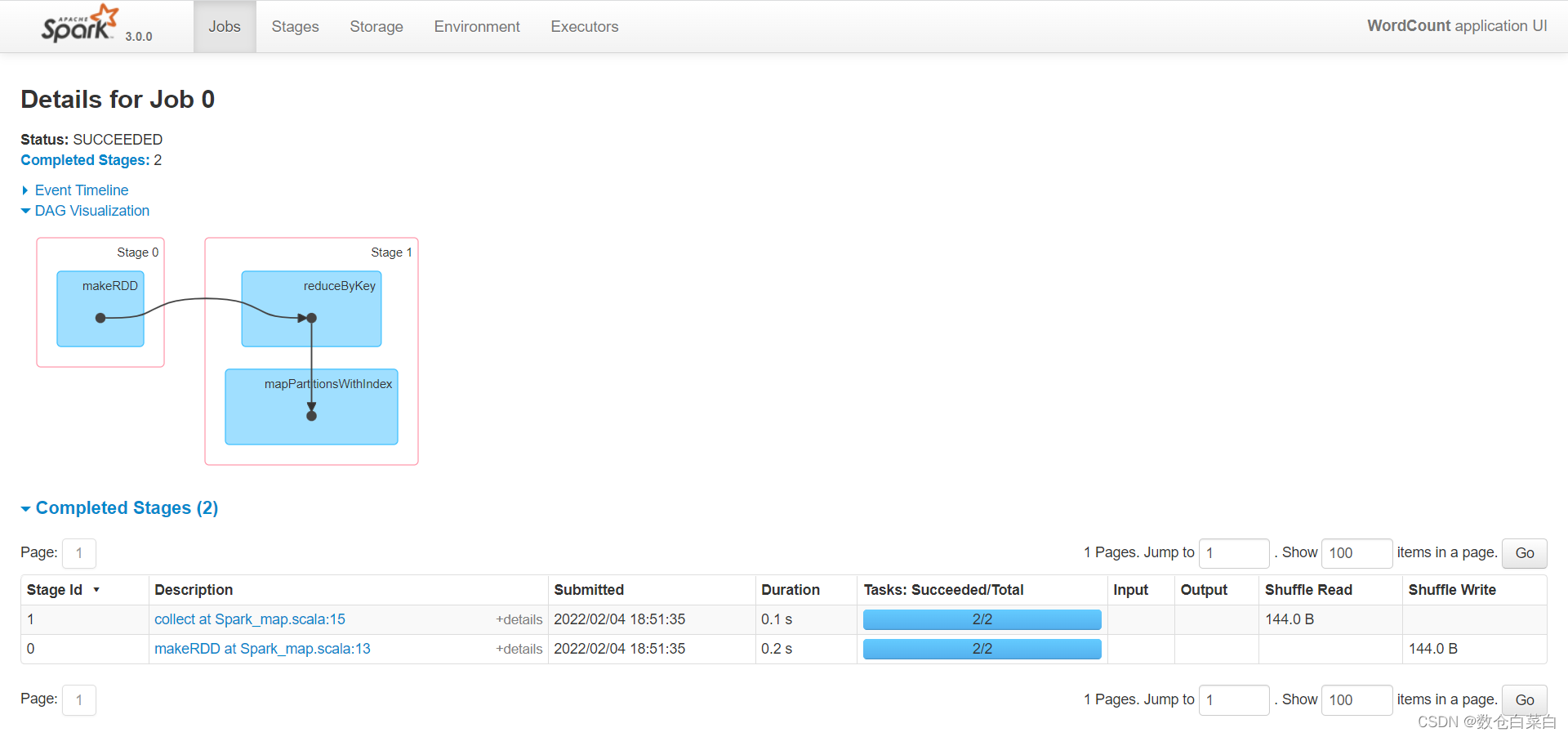
在本地任务里面可以看到DAG(有向无环图),里面有每个算子的执行以及下一步的去向。
groupBYkey
groupByKey对每一个key进行操作,在groupby中,生成的是(key,iter),而这个参数也一样,并不会像reducebykey一样,可以计算出结果。
看一下图解
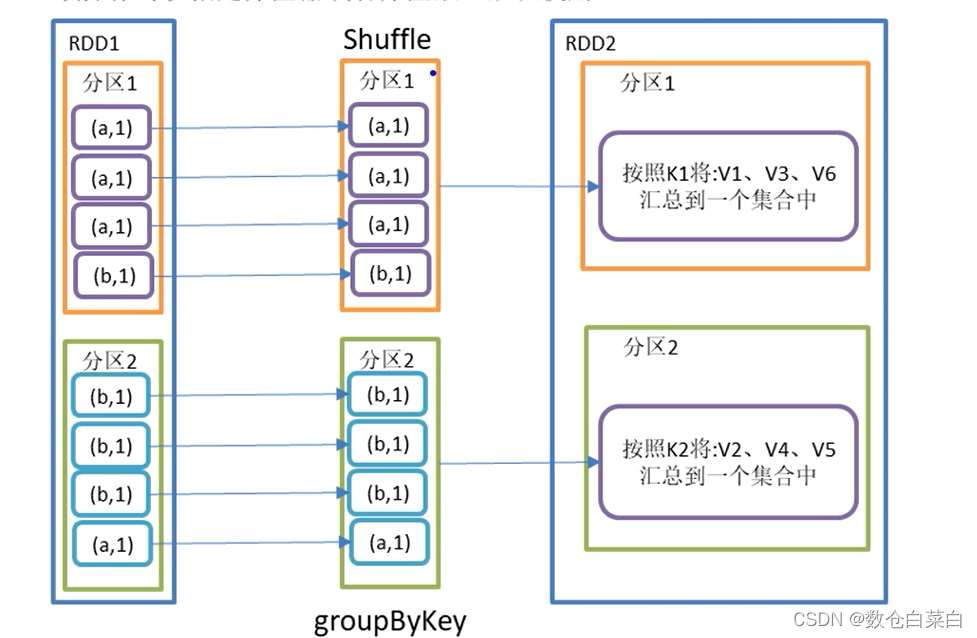
用groupbyKey来计算wordCount
val wordCount = new SparkConf().setMaster("local").setAppName("WordCount")
val sparkContext = new SparkContext(wordCount)
//创建rdd
val value1 = sparkContext.makeRDD(List(("a", 1), ("b", 5), ("a", 12)),2)
//对key进行分组
val value = value1.groupByKey()
// 上面的类型是 [String,Iterable[Int]]
//通过map 转变格式
val value2 = value.map {
case (word, iter) => (word, iter.sum) }
value2.collect().foreach(println(_))
可以看到 reducebykey和groupbykey都可以实现wc,这两种算子都会有shuffle,reducebykey是先在分区里面聚合,然后再一次聚合。但是groupbykey是一直在运算。
就像洪水冲堤坝一样,reducebykey相当于让洪水不会一泻千里,会多次阻挡。
aggregateByKey
aggregateByKey这个算子有三个参数
- zeroValue:给每一个分区的每一种ke'y一个初始值
- seqOP:对每一个分区中用初始值进行迭代value
- combOp:合并每个分区的结果
下面先用aggregateByKey进行wc案例
val wordCount = new SparkConf().setMaster("local").setAppName("WordCount")
val sparkContext = new SparkContext(wordCount)
val value1 = sparkContext.makeRDD(
List(("a", 1), ("b", 5), ("a", 12)),2)
value1.aggregateByKey(0)( (x,y) => x + y, (x,y) => x + y )
.collect().foreach(println(_))
让zeroValue为0
分区内 对相同的key进行累加
分区间 不用分区间相同的key进行累加,细看的话,这个过程就跟reduceByKey的过程一样,都是分区内先进行相加,然后分区间进行相加
下面进行高阶案例
求出每个分区中每个key的最大值,然后再相加
先图解一下
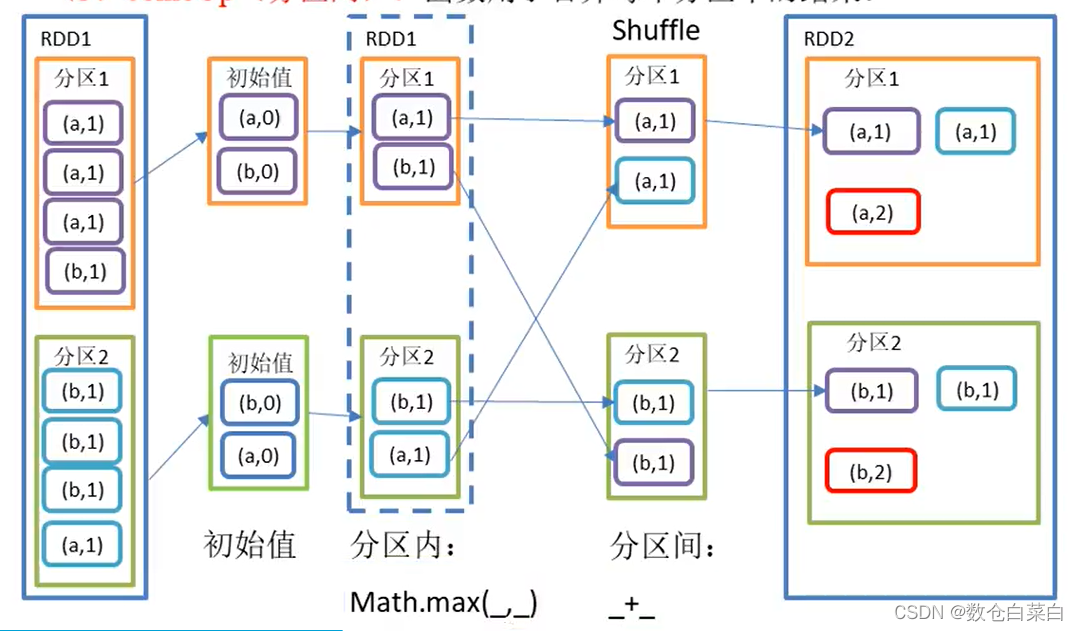
可以看到,会在分区内对每个key先进行操作,找到每个分区内的相同的key的最大值,然后在分区间将相同的key的值进行累加。
val wordCount = new SparkConf().setMaster("local").setAppName("WordCount")
val sparkContext = new SparkContext(wordCount)
val value1 = sparkContext.makeRDD(
List(("a", 1), ("b", 5), ("a", 12)),2)
value1.aggregateByKey(0)(
(x,y) => math.max(x,y), (x,y) => x + y )
.collect().foreach(println(_))
在每一个分区内,找到最大的值,这个寻找,是先和默认值进行比较,比较完之后再与下一个值进行比较。
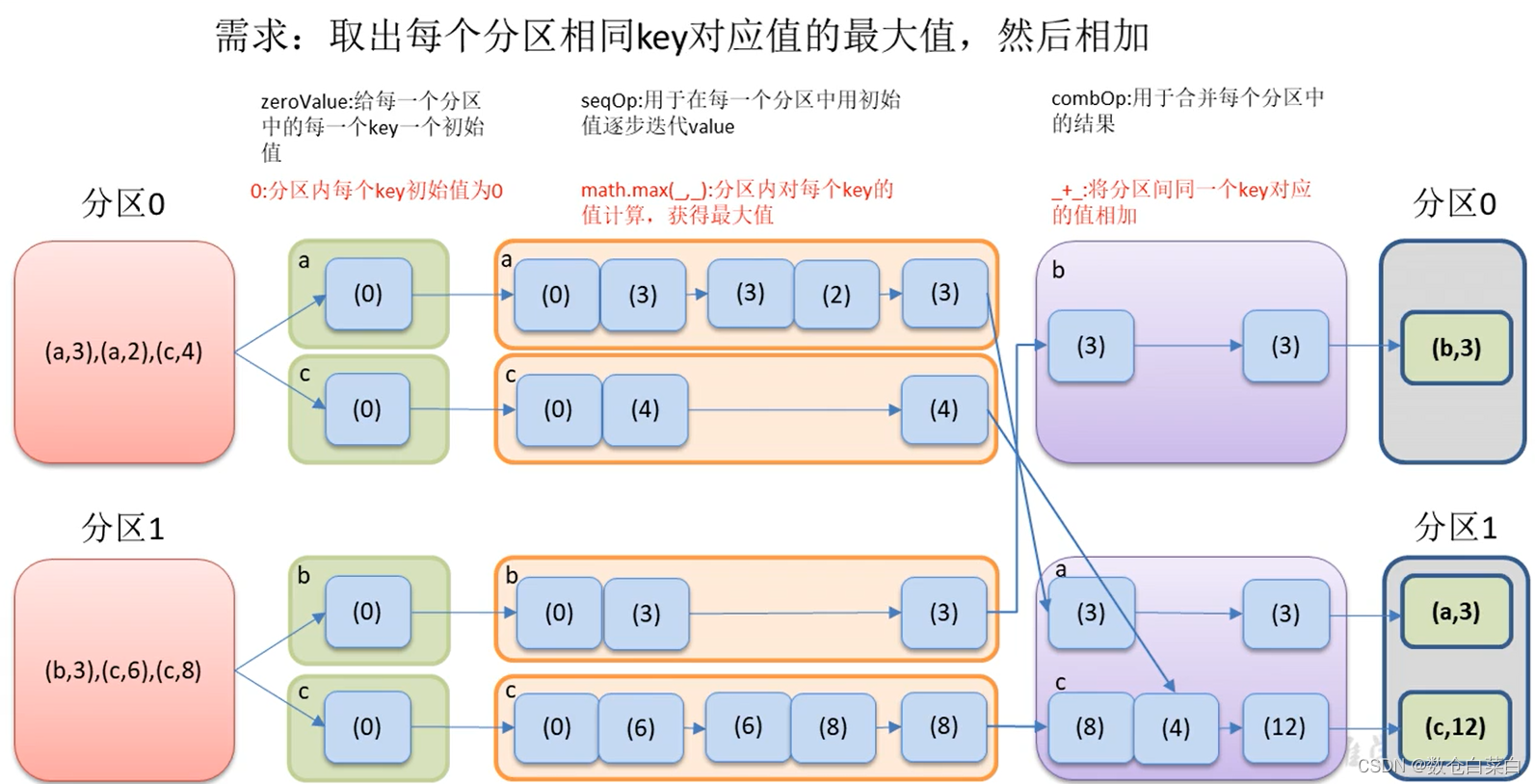
正如上图索斯,要与每一个值进行比较之后,才找到了最大值,而不是一次就找到了最大值。
flodBykey
如果aggregateByKey中的分区内和分区间的规则相同,那么就可以简化为flodByKey.
val dataRDD1 = sparkContext.makeRDD(List(("a",1),("b",2),("c",3)))
val dataRDD2 = dataRDD1.foldByKey(0)(_+_)总结:
今天就到此为止了,本来想继续写来着,但是不行了,我要留到明天了
现在需要做的就是找她聊天,为什么呢?因为想她了,所以不写了,等明天早上努一努,争取十二点之前发一篇,然后下午再发一篇
大家明天再见拉
微信扫描下方的二维码阅读更多精彩内容

每日分享到群里,或者推荐给朋友会得大量积分,机会可以兑换微信零钱红包,具体请点击这里,得到了微信红包可以用来支持大飞哥
大飞哥能不能加鸡腿就看各位了!

开发者微信

开发者微信反馈BUG或者VIP可以添加,其他情况反馈可能不及时,见谅
版权声明
初衷是提供高清手机电脑壁纸等图片素材免费分享下载,禁止商用。图片素材来源网络,版权归原作者所有,若有侵权问题敬请告知我们!
【友情提醒】:
因平台原因不易展示大尺度写真,有的写真展示越少代表此套写真越性感,特别是xiuren等写真每一套写真完整套图50-100张不等。更多内容的欣赏请移步 点击这里
【更多图集移步】:
每日更新-点击这里
漂亮小姐姐-点击这里
性感美女-点击这里
清纯女孩-点击这里
xiuren专栏-点击这里
整站资源下载-点击这里